GemBench Challenge
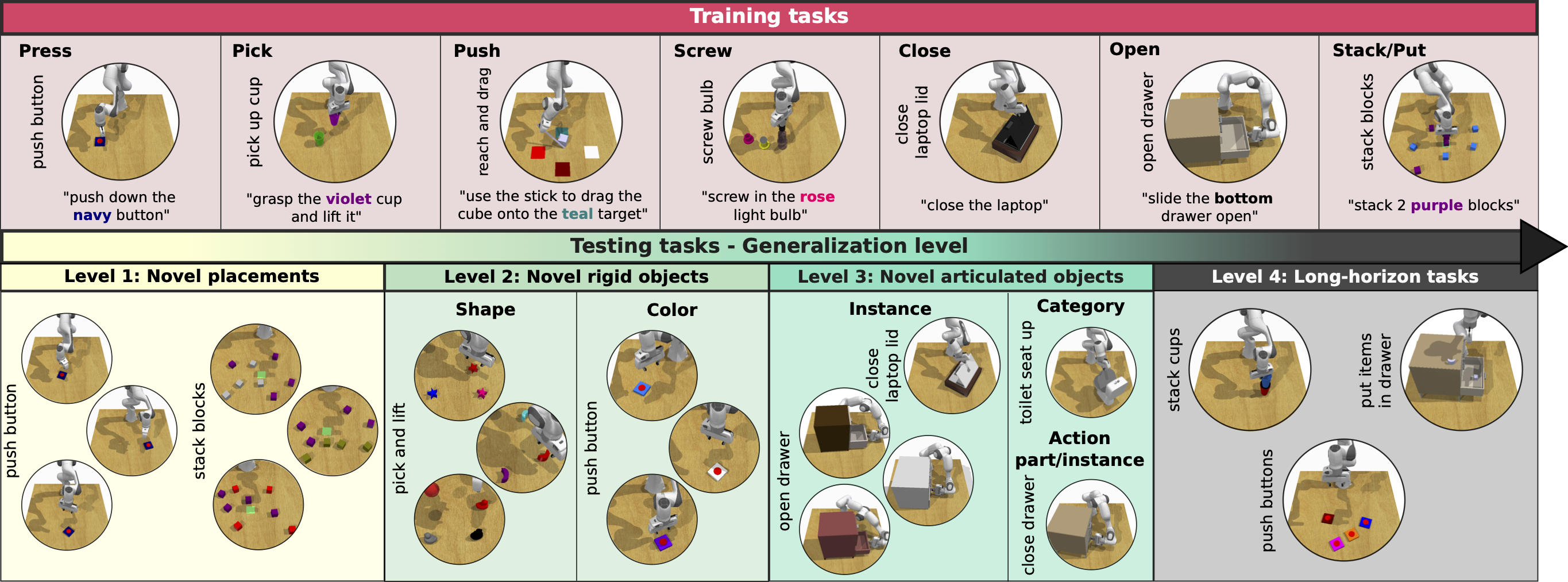
GemBench comprises 16 training tasks with 31 variations, covering seven action primitives. The testing set includes 44 tasks with 92 variations, which are organized into four progressively more challenging levels to systematically evaluate generalization capabilities, namely novel placements, novel rigid object, novel articulated objects, and long-horizon tasks.